A deep dive on the Agent plane. Why harness engineering, not prompts or models, decides whether your agentic system ships.
This is the second piece in a series on enterprise multi-agent architecture. The flagship laid out five planes and a Trust Fabric. This piece goes inside the Agent plane and stays there.
The model was fine. The harness was not.
On April 23, 2026, Anthropic published one of the most instructive engineering postmortems any AI lab has shipped to date. It explained six weeks of degraded performance in Claude Code, a flagship product that thousands of engineering teams use every day. Customers had been complaining since early March that the system felt slower, more forgetful, and noticeably less capable. The investigation, published openly, pointed at three independent root causes, and not one of them was the model.
On March 4, the default reasoning effort for Sonnet 4.6 and Opus 4.6 had been lowered from high to medium to address UI latency issues where the interface appeared frozen during long thinking periods. Anthropic later called this “the wrong tradeoff.” It was reverted on April 7. On March 26, a caching optimization shipped that was supposed to clear old reasoning context once after an hour of session inactivity. A bug caused it to do so every turn for the rest of the session, which made Claude appear forgetful and repetitive. It was fixed on April 10. On April 16, a system prompt instruction was added to reduce verbosity, capping commentary between tool calls. Broader testing later showed it dropped code generation quality by roughly three percent. It was reverted on April 20.
The API and the underlying model weights were not affected. The model was the same model. Three harness-level changes did the damage.
I cite this incident not to single out one company. I cite it because there is no more honest illustration of the thesis of this entire essay. In production agentic systems, the harness is the system. When the harness fails, your customers experience it as the agent failing, the model failing, the product failing. The model is the brain. The harness is the nervous system. When the nervous system is sick, the brain cannot demonstrate its intelligence.
Most engineering teams underinvest in the harness because the harness is invisible when it works. This piece is about making it visible.
What changed in 2026
The harness has always existed. Anyone who has shipped an agent has built one, even if they did not have a name for it. The term itself was coined by Mitchell Hashimoto in scattered public writing and talks through 2024 and 2025, with the often-quoted one-sentence summary: “any time your agent makes a mistake, you take the time to engineer a solution so the agent never makes that mistake again.” What changed in early 2026 is that the name consolidated and the architecture got formalized.
In February 2026, OpenAI published Harness Engineering: leveraging Codex in an agent-first world, which described a five-month internal experiment that started in August 2025. A team that began with three engineers, later growing to seven, shipped a production beta containing roughly one million lines of code. Zero lines were written by human hands. Roughly fifteen hundred pull requests were merged at an average throughput of 3.5 PRs per engineer per day. Throughput increased as the team grew, because a better harness design compounded the value of each additional engineer. The team’s stated philosophy was “humans steer, agents execute.” When something broke, the team did not write code to fix it. They asked: what capability is missing from the harness, and how do we make it legible and enforceable for the agent?
In late 2025 and again in early 2026, Anthropic published research papers documenting what it had built to get Claude to work across long, multi-hour autonomous coding sessions. The answer was not a smarter model. It was a smarter environment around the model.
On March 31, 2026, the field got a different kind of evidence. A missing entry in Anthropic’s .npmignore shipped a sixty-megabyte source map alongside Claude Code v2.1.88 on npm, exposing roughly five hundred thousand lines of TypeScript across nineteen hundred files. Within hours the community had mirrored and dissected it. What the analysis revealed is the most thoroughly documented production harness available anywhere: a radically simple while(tool_call) orchestration loop, roughly thirty-eight built-in tools, a six-layer permission gauntlet, dynamically assembled system prompts split into static cacheable and dynamic per-user halves, and the explicit design discipline of treating the agent’s own memory as “a hint, not truth” to be verified against actual state before action. The takeaway, in the community’s words: building reliable AI agents is primarily an orchestration engineering problem, not a model capability problem. Anthropic issued takedowns. The lessons cannot be unlearned.
Then came the convergence event. On April 8, 2026, Anthropic launched Claude Managed Agents in public beta: three REST endpoints, sandboxed execution, checkpointing, credential scoping, tracing. Notion, Rakuten, and Sentry shipped to production with it. Seven days later, on April 15, OpenAI updated the Agents SDK with a model-native harness, nine sandbox providers, and Codex-style filesystem tools. The two largest frontier labs in the world shipped fundamentally the same architecture inside a week: a clean split between a control plane (the harness) and an execution plane (the sandbox), with a session as the unit of state.
Martin Fowler has since written about it. An arXiv paper formalizes it. The discipline now has a name. The floor for what counts as serious harness engineering just moved up.
That is the context for everything below.
What a harness actually is
A harness is the runtime system around the model that makes the model usable. It is not the model. It is not the agent. It is what turns the model’s raw capability into the agent’s reliable behavior.
The cleanest framing I have found, attributed to Philipp Schmid and now in common use, is that the model is the CPU and the harness is the operating system. The CPU does the computation. The OS manages memory, schedules processes, mediates access to devices, enforces permissions, and handles failures. A naked CPU is not a computer. A naked model is not an agent.
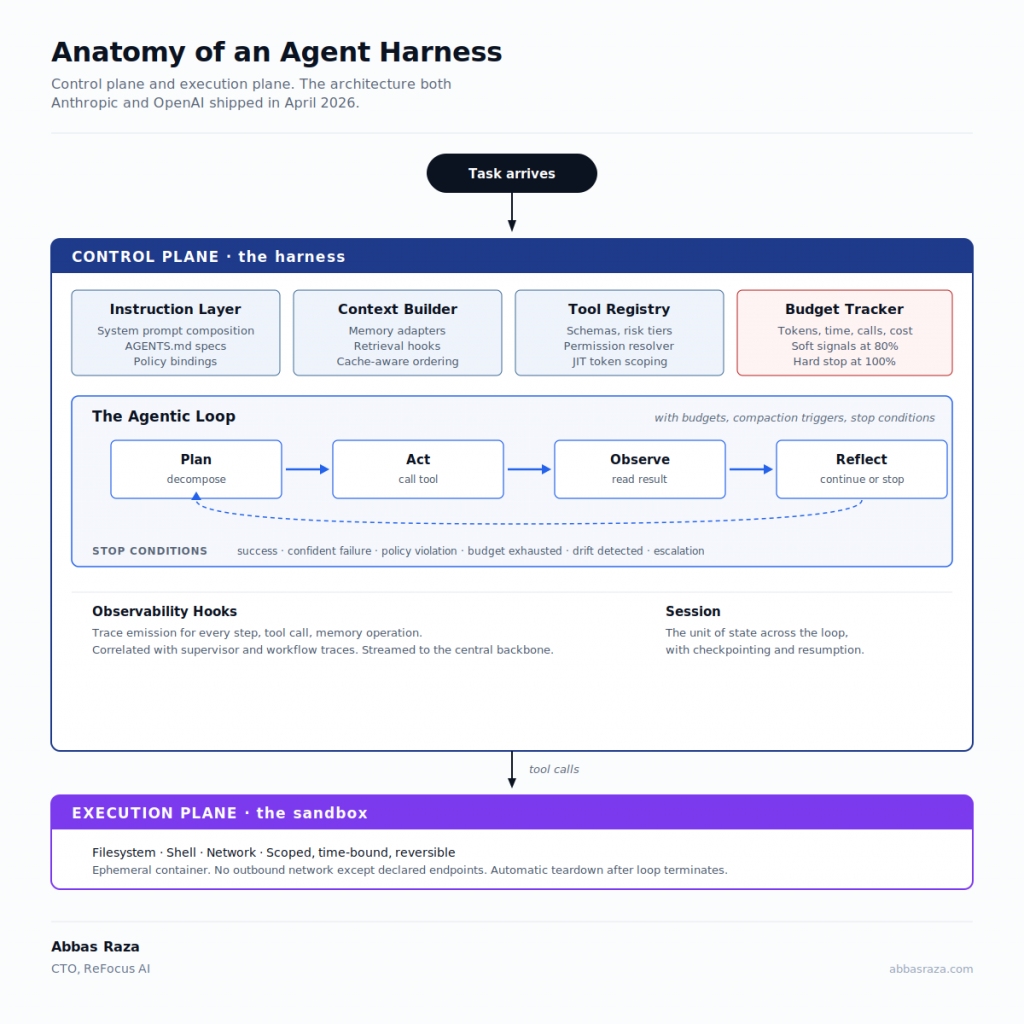
The component model that has consolidated through 2026 contains roughly fifteen modules. I group them into seven functional areas:
Instruction layer. System prompts, machine-readable specification files (the AGENTS.md convention popularized by OpenAI’s Codex team is the canonical example), and the logic that composes them into the actual instructions the model sees on each call. The instruction layer is where most “prompt engineering” lives, but treating it as separate from the harness is a category error. It is the harness’s input layer.
Context builder. The component that assembles working context for each invocation: retrieved knowledge, recent episodic memory, current task state, applicable procedural guidance. The cache-aware ordering of this context is one of the highest-leverage optimizations in the entire stack and is also where the Anthropic March 26 caching bug lived.
Tool registry and permission resolver. The catalog of tools the agent can call, with their schemas, their risk classifications (read-only, financial, destructive), and the policy that decides which tools the agent is allowed to call right now. The permission resolver pulls from the Trust Fabric on every call.
The agentic loop. Plan, act, observe, reflect, with explicit budgets, compaction triggers, and stop conditions. This is the heart of the harness and the most commonly underbuilt part. I treat it as its own section below.
Sandbox and execution plane. The isolated environment in which the agent’s actions actually happen. Filesystem access, shell access, network access, all scoped, time-bound, and reversible. This is the layer that Anthropic and OpenAI cleanly separated from the control plane in their April releases. The clean split is the single most important architectural decision in this space.
Observability hooks. Trace emission for every decision, every tool call, every memory operation. Without this, you cannot debug, you cannot evaluate, you cannot audit, you cannot improve. Observability is not optional.
Budget tracker. Per-task and per-session limits on tokens, tool calls, wall-clock time, and dollar cost. The unsung component that prevents your bug from becoming your invoice.
These seven areas are not optional. A harness missing any one of them is a harness that will fail in production in a way you will not see coming.
Inside the agentic loop
The loop is where ambition meets discipline. Most teams write the loop in a few hours and then spend two quarters discovering all the ways it leaks.
The canonical structure is straightforward. The agent receives a task. It plans an approach. It executes an action against a tool. It observes the result. It reflects on whether to continue, replan, escalate, or stop. Repeat until the goal is achieved or a stop condition fires.
The three things most loops get wrong:
Budgets. The loop needs hard limits on token consumption, wall-clock time, tool calls, and total cost per task. Without these, a single bug in the reflect-and-replan logic will run a retry storm that produces a five-figure invoice before any human notices. A budget tracker that aborts the loop with a clean error and a complete trace is one of the cheapest pieces of engineering you can do and one of the most consequential.
Compaction triggers. Long-running tasks accumulate context. At some point, the context exceeds what fits efficiently in the model’s window, and a naive harness will either fail or pay for very expensive long-context calls forever. A compaction strategy that summarizes older context into structured episodic memory while preserving recent working state is the difference between agents that can run for ten minutes and agents that can run for ten hours. Anthropic’s harness research from late 2025 and early 2026 was substantially about this problem.
Stop conditions. Most loops only stop when the task succeeds. Production loops need to stop on success, on confident failure, on policy violation, on budget exhaustion, on detected drift, and on explicit escalation triggers. Each stop condition emits a different signal to the orchestration layer above. A loop that only knows “done” and “still working” is a loop that will hang or burn money.
The Anthropic Claude Code postmortem maps directly onto these three. The caching bug that dropped reasoning context every turn was a compaction strategy with a bug. The verbosity cap was a context constraint that interacted badly with the loop’s planning step. Real production harnesses fail at exactly these joints.
The taxonomy of harness failures
Two empirical anchors before the taxonomy itself, because they explain why these failure modes are so consequential.
The compound error problem. Dziri et al. demonstrated at NeurIPS 2023 that transformer performance on compositional tasks decays exponentially as complexity grows. The arithmetic is unforgiving. Twenty unguided decisions per task at eighty percent per-step accuracy each yields roughly a one percent chance of an end-to-end correct outcome. Even at ninety-five percent per-step accuracy across twenty steps, overall reliability is only thirty-six percent. Small per-step improvements compound into large outcome differences. Small per-step degradations compound into catastrophic ones. Every failure mode below is a way the harness either accumulates per-step errors or fails to detect them in time.
The harness-is-the-variable proof. In February 2026, the LangChain team published a study using GPT-5.2-Codex as a fixed underlying model on Terminal Bench 2.0, changing only the surrounding harness: system prompts, tools, and middleware. The score moved from 52.8 percent to 66.5 percent. Position on the leaderboard moved from outside the top thirty to fifth. Same model. Same benchmark. Same tasks. The harness was the variable, and it was worth roughly fourteen percentage points of measured performance. The result is the cleanest published quantitative proof of the thesis that the harness is the system. If you only have time to read one external source after this piece, read LangChain’s writeup.
With that as the empirical floor, six failure modes I have seen consistently across deployments, my own and others’:
Memory contamination. Stale, low-quality, or hostile content makes its way into semantic or episodic memory and the agent confidently cites it forever. The fix is governance over the write path, not bigger filters on the read path.
Tool misconfiguration. A tool is registered with the wrong scope, the wrong permission, or the wrong schema. The agent calls it correctly. The world receives the call incorrectly. The fix is treating the tool registry as a versioned artifact with its own review and rollback.
Brittle prompt scaffolding. Tiny changes to system prompts, instruction order, or formatting cause large changes in behavior. Anthropic’s verbosity cap is the textbook public example: a small instruction in the harness’s prompt scaffolding caused a measurable quality regression on production traffic. The fix is eval coverage on every prompt change, not just on every model change.
Missing error recovery. The agent encounters something outside its expected envelope and either crashes silently, retries forever, or escalates to a human who cannot do anything useful with the half-state. The fix is a recovery policy that distinguishes recoverable from terminal, plus a clean handoff protocol when recovery is impossible.
Cache poisoning. A bug in the cache layer causes either wrong context to be served or right context to be evicted at the wrong time. Anthropic’s March 26 caching bug, which kept clearing reasoning sections every turn instead of once per idle hour, is a precise illustration. The fix is treating cache logic as a first-class component with its own tests, not as an optimization to be quietly tuned by whoever is on call.
Cost amplification through retry storms. The reflect step decides to retry. The retry produces another reflect that decides to retry again. The budget tracker is missing. The bill arrives. The fix is the budget tracker, plus exponential backoff with circuit breakers on the retry path.
These six are not exotic. They are the ordinary ways harnesses break. A serious harness engineering practice means you have explicit detection and mitigation for each.
The staffing ratio defended
I claimed in the flagship piece that the right prompt-to-harness engineer ratio is roughly one to four, and that most teams run it inverted. The OpenAI Codex result is the most extreme published validation of this claim that I am aware of.
The Codex team did not start with a brilliant prompt. They started with mediocre output and a harness that did not work well. Over five months, they steadily improved the harness: better repository structure, sharper AGENTS.md specifications, more comprehensive CI invariants, better tool integration, cleaner error recovery. As the harness improved, productivity rose sharply. By the end of the experiment, three engineers had merged roughly fifteen hundred PRs covering about a million lines of production code. When the team grew from three to seven, throughput per engineer increased rather than plateauing. That is the signature of compounding harness investment.
The lesson for any CTO staffing an agent team this year: hire harness engineers, not just prompt engineers. The skills are different. Prompt engineering is closer to writing, editing, and applied linguistics. Harness engineering is closer to distributed systems, platform engineering, and SRE. The best harness engineers I have interfaced with came from infrastructure backgrounds, not ML backgrounds. They understood retries, idempotency, observability, and graceful degradation before they ever saw a model. They learned the model-specific parts in a quarter. The reverse direction takes much longer.
If you are interviewing for harness engineers, the screening question I would ask is not “explain the transformer.” It is “describe the worst distributed systems bug you ever shipped and how you found it.” The answers will tell you everything.
A worked example: the Risk Reassessment agent’s harness
Recall the contract renewal scenario from the flagship. The Renewal Supervisor delegated to four specialist agents, one of which was the Risk Reassessment agent. Its job was to assemble a current view of a vendor’s risk profile by pulling SOC 2 history, security incident records, financial filings, and fresh external signals, then producing a structured risk score.
Here is what its harness contains.
The instruction layer loads two specifications: a global procurement risk policy file (read-only, signed, versioned) that defines what “risk” means in our organization, and an agent-specific specification that describes its inputs, outputs, allowed tools, and escalation triggers. These compose into a system prompt at invocation time, with version stamps embedded for traceability.
The context builder assembles, in cache-friendly order: the static risk policy first (high cache hit rate), then the vendor’s historical risk timeline from episodic memory, then the working context for this specific renewal, then any freshly retrieved external signals. The ordering matters because the first three sections are highly cacheable and the fourth is not. Cache hit rates above sixty percent are the norm for this agent.
The tool registry declares four available tools, each scoped: read SOC 2 documents (read-only, internal), read financial filings (read-only, internal), query news API (read-only, external, rate-limited), and write to draft risk report (write, scoped to this run’s working directory). The permission resolver checks against the Trust Fabric policy before each call. No tool is granted access to anything not declared.
The agentic loop runs with a budget of ten thousand tokens, five minutes of wall-clock time, fifty tool calls, and ten dollars of inference cost. Compaction fires every twenty minutes by summarizing accumulated evidence into a structured intermediate. Stop conditions include “risk score produced,” “missing critical input, escalate,” “policy violation detected,” and “budget exhausted.”
The sandbox is an ephemeral container with no outbound network except to the four declared tool endpoints, no filesystem persistence except the scoped working directory, and an automatic teardown after the loop terminates.
The observability hooks emit a structured trace event for every loop iteration, every tool call, every memory read or write, and every budget update. The trace is shipped to the central observability backbone where it is correlated with the supervisor’s trace and the workflow’s trace.
The budget tracker is checked after every action. If any budget is at 80 percent, a soft signal is emitted to the reflect step suggesting a wrap-up. At 100 percent, the loop terminates with a clean partial-result handoff to the supervisor.
That is what one agent’s harness looks like in actual production. Multiply it across an environment of dozens or hundreds of agents and you start to see why the harness, not the model, is what shapes whether the system works.
What to build first
If your team is six months into building agents and you read this list with a sinking feeling, here is the order I would build the harness in, starting today.
- Stand up tracing first. Before evals, before budgets, before anything else. You cannot improve what you cannot see. Every agent invocation should emit a structured trace by the end of next week.
- Build the budget tracker. Wall-clock, tokens, tool calls, dollars. The day a bad retry loop tries to run a thousand iterations is the day you wish you had built this first.
- Separate the control plane from the execution plane. Even if both run in the same process today, refactor so the agentic loop is one component and the tool execution is another. The clean split is what makes everything else possible.
- Externalize the instruction layer. Get system prompts and instructions out of code and into versioned specification files. Treat them like infrastructure-as-code.
- Add compaction. Long-running sessions need a compaction strategy. Implement it before you ship the agent that needs it.
- Eval the harness, not just the agent. Write tests that mutate the harness (drop a tool, change an instruction, fail a memory read) and assert the agent degrades gracefully. The Anthropic verbosity cap incident would have been caught by this kind of test.
That is roughly a quarter of focused work for a small team. It pays for itself the first time a budget tracker catches a runaway retry, or a clean handoff converts a silent failure into a clean escalation.
Hiring for this
The role is real. Harness Engineer, or Agent Platform Engineer, or whatever your organization names it. What it is not: prompt engineer. What it is: a platform or distributed systems engineer who has learned enough about LLMs to be dangerous.
Where they come from in 2026: SRE backgrounds, infrastructure backgrounds, developer tools backgrounds, sometimes from a strong backend engineering background with a serious applied interest. They are usually not the loudest people on the AI team. They are the ones who care about the cache hit rate, the retry curve, the trace completeness. They build the things that make the system survive Monday morning when an upstream model provider has a partial outage and the on-call engineer has not had coffee yet.
Screen them on infrastructure thinking, not on model trivia. The model trivia is a quarter of learning. The infrastructure thinking is a career.
What this means
The flagship made the case that the model is not the product. The architecture is the product. This piece refines that claim one layer deeper. Inside the architecture, the harness is the system. The model is a remarkable component, increasingly commoditized, increasingly inexpensive, increasingly available in interchangeable forms. The harness is what your team builds, what differentiates how the model behaves on your problem, and what determines whether the system runs reliably enough for the business to depend on it.
In 2026, the two largest frontier labs in the world independently published the same architecture inside a week. That is the field telling you which discipline to invest in.
Build the harness.
Further reading
- Anthropic. An update on recent Claude Code quality reports. Engineering postmortem, April 23, 2026. https://www.anthropic.com/engineering/april-23-postmortem
- LangChain. Improving Deep Agents with Harness Engineering. February 17, 2026. https://www.langchain.com/blog/improving-deep-agents-with-harness-engineering. The 52.8 to 66.5 Terminal Bench result with the model held fixed.
- OpenAI. Harness Engineering: leveraging Codex in an agent-first world. February 2026. https://openai.com/index/harness-engineering/
- OpenAI. A Practical Guide to Building AI Agents. April 2026.
- Dziri, N., Lu, X., Sclar, M., et al. Faith and Fate: Limits of Transformers on Compositionality. NeurIPS 2023. The compound error result.
- Anthropic. Research papers on long-running agent harness design, published through 2025 and 2026.
- Community analyses of the March 31, 2026 Claude Code source map disclosure. The most widely studied production harness implementation publicly available.
- Mitchell Hashimoto. Public writing and talks on harness engineering, 2024 to 2026. Coined the term.
- Cobus Greyling. The Rise of AI Harness Engineering. March 2026.
- Martin Fowler / Birgitta Böckeler. Writing on harness engineering as an architectural pattern, published on martinfowler.com.