A deep dive on the Model plane. Why frontier model choice is the wrong question, what an AI gateway actually does, and how to design for a market that is commoditizing in real time.
This is the third piece in a series on enterprise multi-agent architecture. The flagship laid out five planes and a Trust Fabric. The second piece went deep on the Agent plane and the discipline of harness engineering. This piece goes inside the Model plane and stays there.
The model market broke this week
Last Wednesday, the Wall Street Journal reported that OpenAI is in active discussions to lower its token prices substantially. The reason is not generosity. Anthropic just closed a sixty-five billion dollar Series H at a valuation approaching one trillion dollars, ahead of an IPO filing. Google cut its premium AI Ultra tier from $250 to $200 at I/O on May 19, added a new $100 entry point, and positioned Gemini 3.5 Flash at roughly seventy percent below frontier pricing. Chinese models from DeepSeek, Kimi, and Zhipu are running the same enterprise workloads at roughly one-ninth the cost of US frontier providers. The widely-cited comparison: a workload that costs $4,811 on Anthropic Claude runs for $544 on Zhipu’s GLM.
The model layer is commoditizing in real time. By the time you finish this essay, some of the prices in the paragraph above may already be wrong. The architectural lesson is not which provider to bet on next. It is to stop betting at all.
I have been saying for three years that the model is not the product. The architecture is the product. That claim has aged well. What it requires of you, as a CTO or architect, is a Model plane that does not depend on any one provider being the right answer for any one task at any one moment. You need a portfolio. You need a gateway. You need substitution as a config change. The teams that have this already are spending an afternoon doing what their competitors will spend a quarter doing. The teams that do not have it yet are about to learn the most expensive lesson of 2026.
This piece is the architecture for that lesson.
The thesis
You are not picking a model. You are building a portfolio.
The instinct of most engineering teams is to pick a frontier model the way you would pick a database. Choose carefully, integrate deeply, optimize over years. That instinct was always wrong, and the events of the last six months have made it actively dangerous.
A serious Model plane has four properties. It is multi-provider by default, because any single provider is one outage, one pricing change, one quality regression, or one geopolitical shift away from breaking your business. It is tiered, because the cost gap between a small specialized model and a frontier reasoning model is now between ten and thirty times for tasks where both perform comparably. It is routed, because the right model for classifying a customer message is not the right model for synthesizing a six-source analysis. And it is cached, because in real-world workloads a meaningful share of requests are semantically similar, and you should not pay for the same answer twice.
The mechanical realization of all four properties is an AI gateway sitting between your application code and every model provider. Everything below is what that means in detail.
What changed in 2025 and 2026
A quick walk through the events that have reshaped the Model plane in the last twelve months, because the events are the argument.
January 2026: DeepSeek-R1. A Chinese lab released a reasoning model that matched GPT-4-class performance at roughly one one-hundredth of the inference cost. Within two weeks, every CTO with a single-provider strategy was being asked the same question by their board: how fast can we switch? The teams that could answer “a config change, this afternoon” had built the right architecture. The teams that had to answer “a quarter, maybe two” started a project they could not avoid.
March 2, 2026: Anthropic outage. A multi-hour incident took down Claude.ai, the developer console, and Claude Code worldwide. The Wall Street Journal followed up in April with reporting that Anthropic’s API uptime over the prior ninety days sat at 98.95 percent. The cloud benchmark for serious infrastructure is 99.99 percent. The gap between those two numbers is roughly eight hours of downtime per year versus roughly four days. For an enterprise running production agents on a single provider, that gap is not a footnote. It is a quarterly board question.
March 31, 2026: Claude Code source map leak. A missing entry in Anthropic’s .npmignore shipped roughly five hundred thousand lines of TypeScript across nineteen hundred files. The community confirmed what practitioners suspected: building reliable AI agents is primarily an orchestration engineering problem, not a model capability problem. I covered this in detail in the harness piece. It is relevant here because every architectural lesson it teaches points downstream into the Model plane.
May 19, 2026: Google I/O pricing reset. Google cut AI Ultra from $250 to $200, introduced a $100 tier, and positioned Gemini 3.5 Flash at roughly seventy percent below rival frontier token pricing. Pichai claimed enterprises could save over one billion dollars in annual costs by migrating eighty percent of workloads to Gemini. The number is marketing. The directional signal is real.
June 2026: OpenAI considers price cuts. The Wall Street Journal report last week documented active internal discussions at OpenAI about lowering token prices significantly. This is what the bottom of a price discovery process looks like. The frontier providers are now competing on price, which means the frontier itself is becoming a commodity input.
Throughout: the LiteLLM supply chain attack. A widely-used open-source gateway library was briefly compromised through credential theft. PyPI later reported that the affected versions were downloaded over 119,000 times during the attack window. The lesson is not that LiteLLM is uniquely risky. The lesson is that the gateway layer is now critical infrastructure, which means it is also a high-value target. Owning your own deployment boundary matters more than it did a year ago.
Six events. One direction. The model market is moving from a small number of expensive frontier options toward a large number of substitutable options at sharply diverging price points. Your architecture has to absorb that motion without your application code noticing.
The AI gateway
The AI gateway is the architectural answer to all of the above. It sits between your application code and every model provider you call. Your application calls one address. The gateway routes, caches, falls back, enforces budgets, emits telemetry, and abstracts the differences between providers.
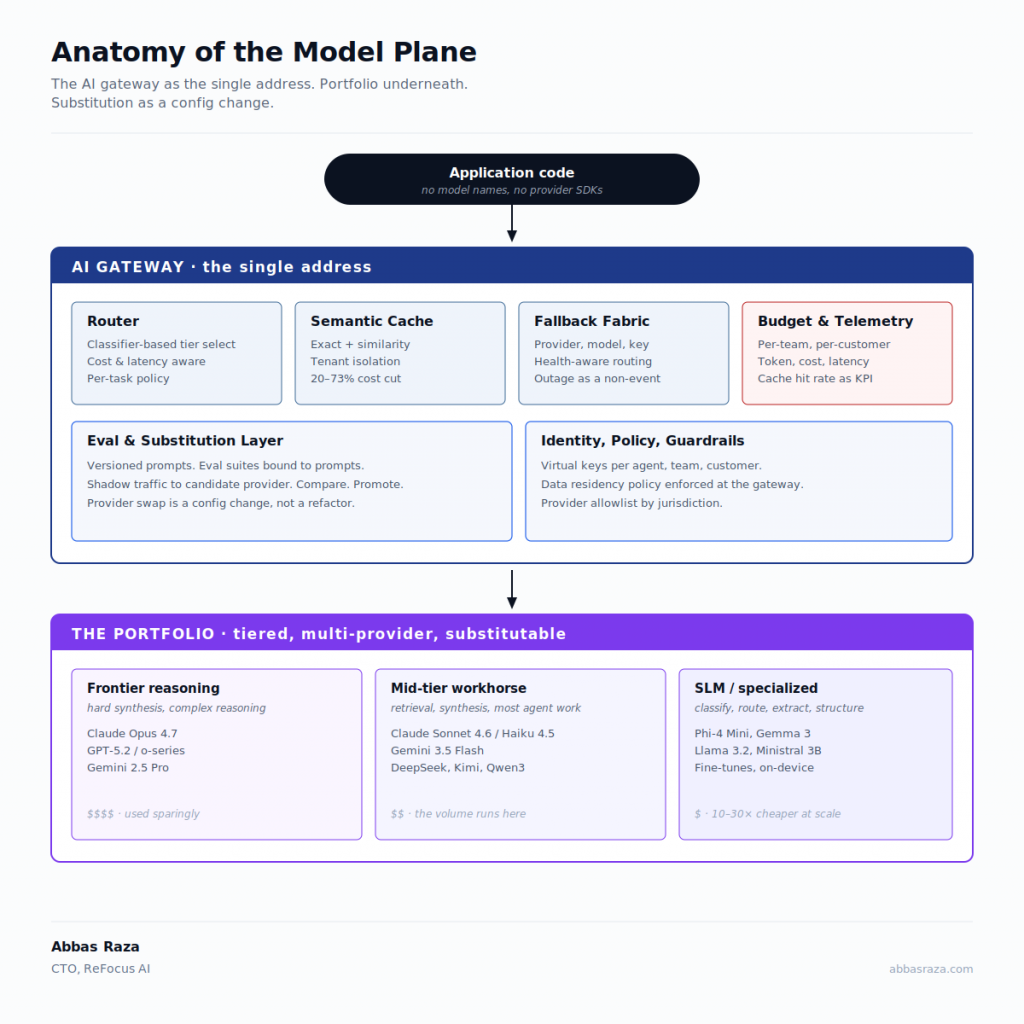
The 2026 gateway landscape has consolidated around roughly half a dozen serious choices: LiteLLM Proxy, Portkey, Cloudflare AI Gateway, Vercel AI Gateway, Kong AI Gateway, OpenRouter, and a handful of newer entrants like Bifrost and Helicone. Each makes different trade-offs on performance overhead, self-hosting flexibility, governance depth, and provider coverage. The choice between them is real but secondary to the choice that comes first, which is to have a gateway at all.
The non-negotiables of a serious gateway:
One endpoint to your application. Your code calls a single address. It does not know about provider SDKs. It does not contain model name string literals. It does not have retry-on-provider-error logic. If a model identifier appears as a string literal anywhere outside your gateway configuration, you have built the wrong abstraction.
Per-team, per-customer, per-agent virtual keys. Each consumer of the gateway gets a scoped key with its own budget, its own provider allowlist, and its own audit trail. When a runaway agent generates a five-figure invoice, you should be able to identify which agent, which workflow, and which customer in under a minute.
Health-aware fallback at three levels. Provider-level (Anthropic is degraded, route to OpenAI), model-level (Opus 4.7 is slow today, route to Sonnet 4.6), and key-level (this customer’s quota is exhausted, route to a backup key). The fallback chain is configurable per request class.
Semantic caching as a first-class component. Not bolted on. AWS-published research on 63,796 real production queries showed that at optimal similarity thresholds, semantic caching delivered an eighty-six percent cost reduction and an eighty-eight percent latency improvement on cached responses, with cache hit rates above ninety percent maintaining ninety-one percent response accuracy. Production deployments routinely report twenty to seventy-three percent token cost reduction depending on workload repetition. Cache hit rate should be a first-class KPI on your engineering dashboard. Most teams do not measure it.
Eval suites bound to prompts, not to models. When a new provider releases a stronger or cheaper option, you should be able to run your evals against it, in shadow, before any production traffic moves. If your evals only work with one provider’s API shape, you have an eval problem and a substitution problem at the same time.
The deeper play is to design the entire gateway for substitution. Provider swap should be a configuration change followed by a shadow comparison followed by a graduated promotion. The teams that get this right will spend an afternoon doing what their competitors spend a quarter doing.
Tiering: the portfolio inside the portfolio
Multi-provider is half the picture. The other half is tiering inside the portfolio.
There are three tiers, and almost every production workload uses all three.
Frontier reasoning. Claude Opus 4.7, GPT-5.2 and the o-series, Gemini 2.5 Pro. Used sparingly, for the hardest synthesis, the most consequential decisions, the work where reasoning quality is the bottleneck. Even inside one provider’s lineup, the price spread between frontier and mid-tier is now severe. Anthropic’s Claude Haiku 4.5 is roughly eighteen times cheaper than Claude Opus 4.7 as of April 2026 pricing. That eighteen-times spread inside one vendor’s catalog is the tiering argument in numerical form.
Mid-tier workhorse. Claude Sonnet 4.6, Claude Haiku 4.5, Gemini 3.5 Flash, the better open-weights mid-tier options. This is where most of the volume runs. Retrieval-shaped work. Synthesis with bounded context. Routine agent steps. Most production reasoning lives here.
SLM and specialized. Phi-4 Mini, Gemma 3, Llama 3.2 1B and 3B, Mistral Ministral 3B, Qwen3. Used for classification, routing, structured extraction, format conversion, intent detection, content moderation. Often fine-tuned on your data and hosted on your infrastructure. The economics are striking. Running a private SLM endpoint for ten thousand daily queries typically costs $500 to $2,000 per month. The equivalent workload on frontier APIs runs $5,000 to $50,000 per month, a five-to-twenty-times gap that widens with volume.
The architectural move is to route by task complexity, not by team preference. A classifier-based router sits in front of the gateway and decides, per request, which tier and which provider gets the call. The classifier itself is usually a small fast model. Cost-aware routing, latency-aware routing, and quality-aware routing are all variations on this theme. The teams that route well report production cost reductions in the forty to seventy percent range without measurable quality regression. The teams that route everything to the frontier are paying for capability they do not need on most of their traffic.
A pattern worth naming that is starting to spread through 2026: speculative decoding. A small fast model drafts a sequence of tokens. A frontier model verifies and either accepts or corrects. The net effect is roughly two to three times speedup on inference with no measurable quality loss. The harness layer makes this trivial to implement once the gateway is in place. The model layer’s job is to make both models available behind one address.
The Chinese model surge and what to do about it
Most Western CTOs have not seriously evaluated DeepSeek, Kimi, or Zhipu yet. The reasons are partly geopolitical caution, partly data residency concern, partly the simple inertia of an existing vendor relationship. Those reasons are not wrong. They are also not sufficient as an architectural posture.
The numbers are stark. DeepSeek-R1 matches GPT-4-class reasoning at roughly one-hundredth the inference cost. Zhipu’s GLM handles workloads at roughly one-ninth the cost of equivalent Anthropic Claude calls. Qwen3 is competitive with Western mid-tier models on most benchmarks. Kimi handles long-context tasks at price points that no Western provider can match today. The capability is real. The price arbitrage is real. And the gap is wide enough that boards have started asking about it directly.
The honest architectural answer is not to migrate workloads wholesale to Chinese providers. The honest answer is also not to ignore them. The answer is the same answer the gateway gives to every provider question: keep your options open.
In practice, this means three things.
Make Chinese model providers available behind your gateway. Not necessarily for production traffic today. For evaluation. For benchmark runs. For workloads where data residency and regulatory constraints do not apply. The gateway abstraction makes the cost of having them available roughly zero. The cost of not having them available, when your board asks why a competitor’s unit economics look better than yours, is high.
Set provider allowlists per workload sensitivity tier. A jurisdiction-aware policy at the gateway level lets you route customer-data-bearing traffic to providers with the right contractual and residency posture, while routing non-sensitive evaluation traffic anywhere. The Trust Fabric piece will cover this in more detail. The Model plane’s job is to make the policy enforceable.
Treat the geopolitical landscape as a variable, not a constant. Export controls shift. Data residency rules shift. Provider availability shifts. Architectures that depend on a constant geopolitical landscape are not architectures, they are bets. A gateway with a multi-provider portfolio is the only architectural posture that survives the next four years intact regardless of how the politics actually go.
The summary version, for the CEO who reads only this paragraph: you do not need to use Chinese models. You need to be able to use them if and when you decide to. That capability is what the gateway gives you.
Semantic caching: the unsung component
The cheapest call is the one you do not make.
Semantic caching is the practice of recognizing that two requests with different wording have the same meaning, and serving the cached response for both. It is not exact-match caching, which is what most teams build first and which catches roughly nothing in real production traffic. It is similarity-based caching using vector embeddings, with a configurable similarity threshold per request class.
The production numbers are excellent. The AWS research I cited above (63,796 real chatbot queries) is the cleanest published result. Eighty-six percent cost reduction. Eighty-eight percent latency improvement. Cache hit rates above ninety percent at high similarity thresholds, with response accuracy still above ninety-one percent. Academic research on the GPT Semantic Cache implementation reported hit rates between 61.6 and 68.8 percent across query categories with positive hit accuracy exceeding ninety-seven percent. Most production teams running this pattern report twenty to seventy-three percent token cost reduction depending on how repetitive their workload is.
A few design rules that have earned their place:
Dual-layer caching. Exact-match hash first, then semantic similarity. Exact matches are free to look up and produce no false positives. Semantic matches are slightly more expensive and require a confidence threshold. Run them in that order.
Tenant-scoped cache isolation. Cache entries scoped per customer, per agent, or per virtual key. A response cached for one tenant should never be served to another. The gateway is where this isolation lives.
Per-class similarity thresholds. A factual question can serve a cached response at a moderate similarity threshold. A code generation request needs a much higher threshold or no cache at all. The threshold is a per-route configuration, not a global constant.
Cache hit rate as a first-class KPI. Track it per agent, per workflow, per customer. When the hit rate drops, something has changed in the workload distribution and you want to know about it. When the hit rate rises sharply, you may be over-caching and degrading quality. The metric is a signal, not a target.
Most teams I have seen underbuild the cache layer. The cost of building it well, relative to the cost of running production agents without it, is small. The unit economics improve immediately on day one.
No model names in application code
This deserves its own short section because it is the single most consequential discipline in this entire piece, and the violation is the single most common production failure mode I see in agent codebases.
Your application code should not contain a model identifier as a string literal. Ever. Not claude-opus-4-7. Not gpt-5.2. Not gemini-2.5-pro. Not deepseek-reasoner. Not even in comments. Model names live in gateway configuration files. They are deployment artifacts, not source code.
The reason is the same reason database hostnames live in config rather than code. The string is a binding between your code and an external dependency that you do not control. When the external dependency changes (because of a price cut, an outage, a deprecation, a quality regression, or a strategic shift on either side), you want to swap the binding with a config change and a redeploy, not with a refactor. If your application code knows the name of the model it is calling, you have built a refactor where you could have built a config flag.
The deeper version of this rule: your application code should not even know which provider it is calling. It calls the gateway. The gateway decides. The application’s only requirements on the model layer are the input shape and the output shape. Everything else is gateway concern.
When the next frontier model release lands, the teams that have this discipline will run their eval suite against the new model that afternoon, decide whether to promote it, and ship the change with a config update. The teams that do not have this discipline will spend a quarter doing the same work. The discipline costs almost nothing to put in place at the start. It is nearly impossible to retrofit at scale.
What I would do differently
If this piece reads as if I figured this out in advance, I have failed at writing it honestly. The lessons below are the ones I paid for. I share them in the hope that they cost you less.
I picked too early. In our early architecture, I committed to one provider as the primary and treated others as secondary. The commitment showed up in code, in evals, in tooling, in vendor relationships. It took us a quarter to unwind once the market moved. The right posture from day one is to treat every provider as equal-class behind the gateway. Preferences belong in routing policy, not in architecture.
I underbuilt the cache for too long. We had agents in production for six months before we built semantic caching properly. The amount of money that ran through the API in that window, on requests we should have served from cache, would have funded a small team for a quarter. Build the cache early. Measure the hit rate. Tune it as part of normal operations.
I overestimated frontier models on routine work. For classification, extraction, routing, and structured generation, a well-tuned SLM running on cheap inference often beats a frontier model on the three metrics that matter in production: latency, cost, and reliability. We learned this the slow way. Default to small. Justify the use of frontier on each route.
A worked example: the Risk Reassessment agent
Recall the contract renewal scenario from the flagship piece. The Renewal Supervisor delegated to four specialist agents, one of which was the Risk Reassessment agent. Its job was to assemble a current view of a vendor’s risk profile by pulling SOC 2 history, security incident records, financial filings, and fresh external signals, then producing a structured risk score.
Here is what its Model plane usage looks like across a quarter of production traffic.
The agent makes seven distinct kinds of model calls. Three are SLM tier: a classifier that decides whether incoming external signals are relevant to risk, a structured extractor that pulls fields from raw documents, and a quick sentiment scorer for news mentions. Four are mid-tier: synthesizing the security incident timeline, reconciling financial signals against the vendor’s stated posture, drafting the structured risk score, and producing the natural-language summary that flows into the Communication agent. Frontier tier is reserved for one specific case: when the diagnostic agent’s signal-conflict detector flags an unusual pattern that no playbook covers, the case escalates to a frontier reasoning model for a one-shot analysis. That escalation happens on roughly four percent of cases.
Across a quarter, the agent’s cache hit rate on routine pattern matches runs around fifty-five percent. Its blended inference cost per case is roughly seventy percent below what it would be if every call went to a frontier model. Its tail latency is well-bounded because most calls hit either the cache or an SLM. When Anthropic had its March 2 outage, the agent kept running, because the gateway failed over to a secondary provider at the model-tier level and the application code never noticed.
Multiply this pattern across an environment of dozens of agents and you start to see why the Model plane, properly designed, is the difference between unit economics that work and unit economics that do not.
The 90-day move
If you are reading this and wondering where to begin, here is what I would do this quarter.
- Stand up the AI gateway. Pick one, install it, route every model call in your codebase through it within four weeks. No exceptions. No “we will migrate the legacy paths later.” Everything goes through it. This is the keystone investment.
- Audit every model name in your application code. Find every string literal that names a model. Move all of them into gateway configuration. Add a CI check that fails the build if a model name appears in application code.
- Build the semantic cache. Dual-layer (exact then similarity). Tenant-scoped. Measure the hit rate from day one. Make it visible on your engineering dashboard.
- Add at least one non-primary provider. Whichever provider you currently call most heavily, add a second from a different lab. Get both running through the gateway. Set up a shadow traffic mechanism so you can compare them on real workload at any time.
- Set per-team budgets at the gateway. Hard caps with soft signals at eighty percent. A bad day on a misconfigured agent should not produce a five-figure invoice. The cap is a feature, not a constraint.
That is roughly a quarter of focused work for a small team. The teams I have watched do this report payback inside the first month from cache hit rate alone, and substantially more once tiered routing is in place.
What this means
The flagship made the case that the model is not the product. The architecture is the product. The harness piece refined that claim one layer deeper, into the runtime scaffolding that turns a model into a reliable agent. This piece refines it one layer further, into the model layer itself.
You are not picking a model. You are building a portfolio. The model market is commoditizing in real time, and the architecture that survives the commoditization is the architecture that absorbs it invisibly to the application code. Every event of the last six months, the DeepSeek release, the Anthropic outage, the Google price cut, the OpenAI pricing pressure, the Chinese model surge, the supply chain attack on LiteLLM, points to the same conclusion. The model layer is now critical infrastructure, and critical infrastructure should be designed for substitution.
Build the gateway. Stand up the tiers. Cache aggressively. Keep your options open. The next move in the model market is already in motion, and you cannot know which direction it will take. What you can know is whether your architecture is ready for any direction it goes. That readiness is the work.
The next piece in this series goes deep on the Memory and Knowledge plane, which is what the Model plane reads from and writes to, and which is where most agentic deployments quietly fail.
Further reading
- Wall Street Journal. Reporting on OpenAI token pricing discussions, June 2026. Reporting on Anthropic API uptime, April 2026.
- Anthropic. An update on recent Claude Code quality reports. Engineering postmortem, April 23, 2026. https://www.anthropic.com/engineering/april-23-postmortem
- LangChain. Improving Deep Agents with Harness Engineering. February 17, 2026. https://www.langchain.com/blog/improving-deep-agents-with-harness-engineering
- DeepSeek. DeepSeek-R1 technical report. January 2026. The model that reset frontier pricing.
- AWS. Published research on semantic caching across 63,796 real chatbot queries. 2026.
- Google. I/O 2026 keynote and pricing announcements. May 19, 2026.
- Anthropic, OpenAI, Google. Public pricing and model cards for Claude Opus 4.7, Claude Sonnet 4.6, Claude Haiku 4.5, GPT-5.2, Gemini 2.5 Pro, Gemini 3.5 Flash. As of June 2026.
- Microsoft. Phi-4 and Phi-4 Mini model documentation. Meta. Llama 3.2 1B and 3B model cards. Alibaba. Qwen3 family. Mistral. Ministral 3B.
- The 2026 LiteLLM PyPI compromise. PyPI incident report on download counts during the attack window.